L’ADN (Deoxyribonucleic acid) est une molécule qui contient les instructions biologiques uniques qui distinguent chaque espèce. Au cours de la reproduction, les organismes adultes transmettent leur ADN, ainsi que les instructions qu’il contient, à leur progéniture.
Où se trouve l’ADN ?
Chez les espèces eucaryotes, l’ADN est situé dans une région spécifique de la cellule appelée le noyau. En raison de la petite taille de la cellule et de la présence de plusieurs molécules d’ADN par cellule, chaque molécule d’ADN doit être soigneusement emballée. Cette structure emballée d’ADN est connue sous le nom de chromosome. L’ADN se déroule pendant la réplication afin de pouvoir être copié.
Au cours des autres phases du cycle cellulaire, l’ADN se déroule également afin que ses instructions puissent être utilisées pour la synthèse des protéines et d’autres fonctions biologiques. En revanche, pendant la division cellulaire, l’ADN se présente sous forme de chromosomes compacts afin de pouvoir être transféré dans de nouvelles cellules. Les chercheurs appellent l’ADN situé dans le noyau d’une cellule l’ADN nucléaire. L’ensemble de l’ADN nucléaire d’un organisme est appelé son génome.
Les êtres humains et d’autres organismes sophistiqués comprennent une petite quantité d’ADN dans des structures cellulaires appelées mitochondries, en plus de l’ADN présent dans le noyau. Les mitochondries produisent l’énergie dont une cellule a besoin pour fonctionner normalement.
Dans la reproduction sexuée, les organismes héritent de la moitié de leur ADN nucléaire de chaque parent. En revanche, les organismes héritent de la totalité de leur ADN mitochondrial de leur mère. Cela est dû au fait que seuls les ovules, et non les spermatozoïdes, conservent leurs mitochondries lors de la fécondation.
De quoi est composé l’ADN ?
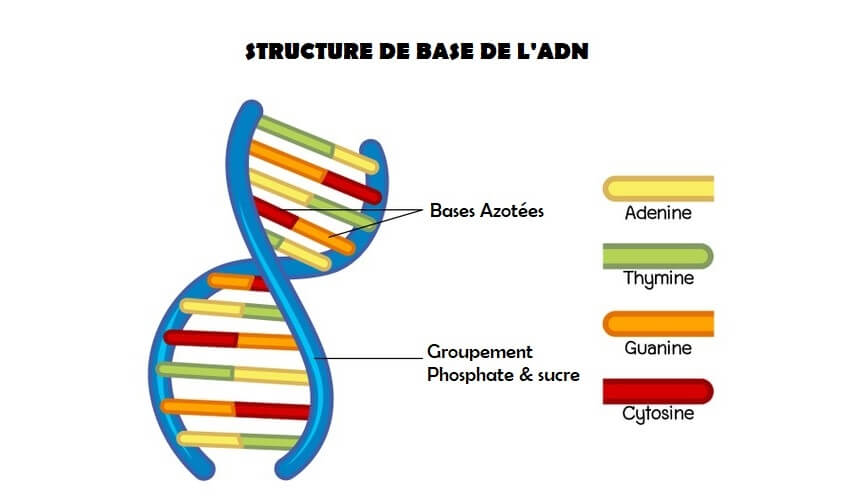
L’ADN est composé d’éléments chimiques appelés nucléotides. Ces blocs de construction sont constitués de trois éléments : un groupe phosphate, un groupe sucre et une des quatre bases azotées. Pour construire un brin d’ADN, les nucléotides sont réunis en chaînes comportant alternativement des groupes phosphate et sucre.
L’adénine (A), la thymine (T), la guanine (G) et la cytosine (C) sont les quatre types de bases azotées présentes dans les nucléotides (C). La séquence de ces nucléotides définit les instructions biologiques contenues dans un brin d’ADN. Par exemple, la séquence ATCGTT peut donner des instructions pour des yeux bleus, mais la séquence ATCGCT peut donner des instructions pour des yeux bruns.
L’ensemble du manuel d’instructions de l’ADN d’un être humain, ou génome, se compose d’environ 3 milliards de bases et de 20 000 gènes répartis sur 23 paires de chromosomes.
Que fait l’ADN ?
L’ADN comprend les instructions nécessaires au développement, à la survie et à la reproduction d’un organisme. Pour accomplir ces tâches, les séquences d’ADN doivent être traduites en messages qui peuvent être utilisés pour construire des protéines, les molécules complexes responsables de la majorité du travail dans notre corps.
Un gène est une séquence d’ADN qui comprend des instructions pour produire une protéine. Chez l’homme, la taille d’un gène peut varier de 1 000 à 1 million de bases environ. Environ 1 % de la séquence d’ADN est constituée de gènes. En dehors de ce pourcentage, les séquences d’ADN déterminent quand, comment et en quelle quantité une protéine est produite.
Comment les séquences d’ADN sont-elles utilisées dans la synthèse des protéines ? Dans un processus en deux étapes, les protéines sont synthétisées à partir des instructions de l’ADN. D’abord, des enzymes lisent les informations contenues dans une molécule d’ADN et les transcrivent en ARNm, ou acide ribonucléique messager.
Les informations contenues dans la molécule d’ARNm sont ensuite traduites dans le « langage » des acides aminés, les éléments constitutifs des protéines. Ce langage indique à la machinerie protéique de la cellule la séquence précise des liaisons entre les acides aminés nécessaires pour générer une protéine particulière. Il s’agit d’une tâche difficile car il existe 20 types différents d’acides aminés, qui peuvent être arrangés de diverses manières pour produire un large éventail de protéines.
Qui a découvert l’ADN ?
À la fin des années 1800, le biochimiste suisse Frederich Miescher a observé pour la première fois l’ADN. Cependant, près d’un siècle s’est écoulé avant que les scientifiques ne déchiffrent la structure de la molécule d’ADN et ne réalisent son rôle vital en biologie.
Les scientifiques se sont disputés pendant de nombreuses années pour savoir quelle molécule portait les instructions fondamentales de la vie. La plupart pensaient que l’ADN, en tant que molécule, était trop élémentaire pour remplir une fonction aussi cruciale. Ils affirmaient au contraire que les protéines étaient plus à même de remplir cette tâche essentielle en raison de leur plus grande complexité et de leur plus grande variété de formes.
En 1953, James Watson, Francis Crick, Maurice Wilkins et Rosalind Franklin ont établi l’importance de l’ADN grâce à leurs recherches. Les scientifiques ont découvert la forme en double hélice de l’ADN en analysant les schémas de diffraction des rayons X et en construisant des modèles. Cette structure permet à l’ADN de transmettre des informations biologiques d’une génération à l’autre.
Qu’est-ce que l’ADN en double hélice?
L’expression « double hélice » est utilisée par les scientifiques pour caractériser la structure moléculaire torsadée à deux brins de l’ADN. Cette structure, qui ressemble à une échelle torsadée, offre à l’ADN la capacité de transmettre des instructions biologiques avec une précision exceptionnelle.
Pour une compréhension chimique de la double hélice de l’ADN, visualisez les côtés de l’échelle comme des brins constitués de groupes sucre et phosphate alternés qui vont dans des directions opposées. Chaque « barreau » de l’échelle est constitué de deux bases azotées liées par des liaisons hydrogène. En raison de l’extrême spécificité de cette forme d’appariement chimique, la base A s’accouple toujours avec la base T, et la base C s’apparie toujours avec la base G. Si vous connaissez la séquence des bases sur un brin d’une double hélice d’ADN, il est facile de déterminer la séquence des bases sur l’autre brin.
La structure inhabituelle de l’ADN permet à la molécule de se copier pendant la division cellulaire. Lorsqu’une cellule se prépare à se diviser, la double hélice d’ADN se sépare en deux brins simples. Ces brins simples servent de modèles pour la construction de deux nouvelles molécules d’ADN double brin, chacune étant une copie exacte de la molécule d’ADN d’origine. Au cours de ce processus, une base A est ajoutée là où il y a un T, une base C là où il y a une base G, et ainsi de suite, jusqu’à ce que chaque base ait à nouveau un partenaire.
En outre, pendant la synthèse des protéines, la double hélice se déroule pour permettre à un seul brin d’ADN de servir de modèle. Ce brin matrice est ensuite traduit en ARN messager (ARNm), une molécule qui transmet des instructions essentielles à la machinerie de synthèse des protéines de la cellule.
Articles Similaires:
- De quoi est composé le noyau cellulaire?
- De quoi est composé l’oxygène?
- De quoi est composé un microprocesseur?
- De quoi est composé le carbone?
- De quoi est composé l’acier?
- De quoi est composé un steak végétal?
- De quoi est composé un hélicoptère?
- De quoi est composé l’hélium?
- De quoi est composé un muscle?
- De quoi est fait le collagène?